

实际工作中常用SQL
查看版本
sql
select version()数据准备
shell
CREATE TABLE `employee` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(255) DEFAULT NULL,
`salary` decimal(10,2) DEFAULT NULL,
`department` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8 COLLATE=utf8_bin;
INSERT INTO `test`.`employee`(`id`, `name`, `salary`, `department`) VALUES (1, 'Joe', 70000.00, '研发部');
INSERT INTO `test`.`employee`(`id`, `name`, `salary`, `department`) VALUES (2, 'Henry', 80000.00, '研发部');
INSERT INTO `test`.`employee`(`id`, `name`, `salary`, `department`) VALUES (3, 'Sam', 60000.00, '研发部');
INSERT INTO `test`.`employee`(`id`, `name`, `salary`, `department`) VALUES (4, 'Max', 90000.00, '研发部');
INSERT INTO `test`.`employee`(`id`, `name`, `salary`, `department`) VALUES (5, 'Janet', 69000.00, '人事部');
INSERT INTO `test`.`employee`(`id`, `name`, `salary`, `department`) VALUES (6, 'Randy', 85000.00, '人事部');
INSERT INTO `test`.`employee`(`id`, `name`, `salary`, `department`) VALUES (7, 'Eva', 85000.00, '人事部');时间相关
Date和字符串互转
sql
-- Date转字符串
select created_time,DATE_FORMAT(created_time, '%Y-%m-%d'),DATE_FORMAT(created_time, '%Y-%m-%d %H:%i:%s') from items;
-- 字符串转Date
SELECT STR_TO_DATE('2023-07-12', '%Y-%m-%d'),STR_TO_DATE('2023-07-12 14:30:00', '%Y-%m-%d %H:%i:%s');Date和时间戳互转
sql
-- 秒转Date & 毫秒转Date
SELECT FROM_UNIXTIME(1688301600),FROM_UNIXTIME(1688301600000 / 1000);;
-- Date转秒
SELECT UNIX_TIMESTAMP(created_time) FROM items;分组取前三
开窗函数
以下是一个使用ROW_NUMBER()的例子,它会为每个分组内的行分配一个唯一的序号,即使值相同也会被分配不同的序号。
sql
SELECT *
FROM (
SELECT department,name, salary,
ROW_NUMBER() OVER (PARTITION BY department ORDER BY salary DESC) AS row_num
FROM employee
) AS tt
WHERE row_num <= 3;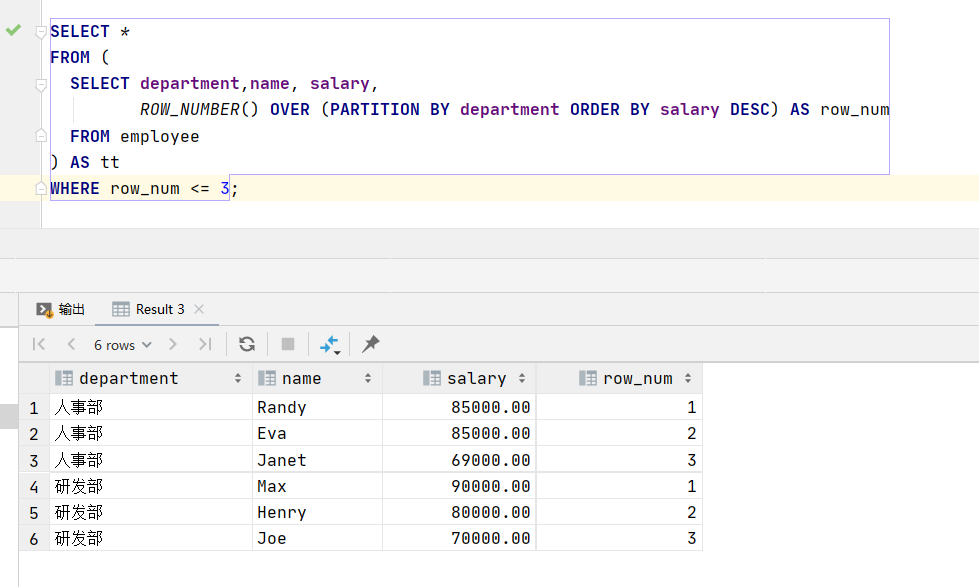
如果你想保留重复值的相对顺序,并且只是为了排序,不需要分配唯一序号,可以使用DENSE_RANK():
sql
SELECT department,name, salary,
DENSE_RANK() OVER (PARTITION BY department ORDER BY salary DESC) AS row_num
FROM employee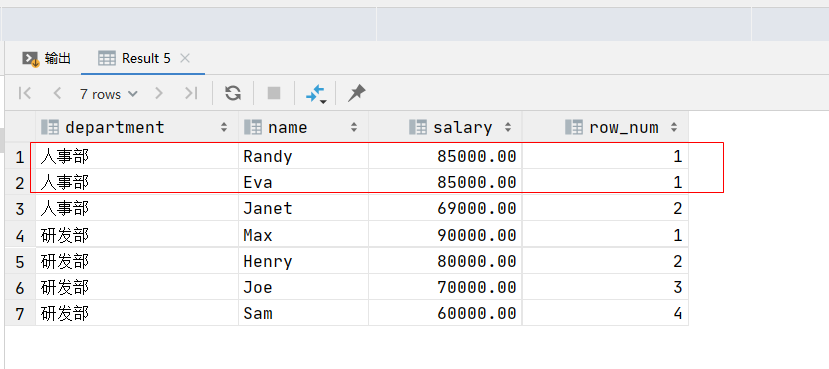
普通写法
-- 部门分组取薪水前三的,但是这样写不严谨,对于并列的会出现多条
sql
SELECT
e.`department` AS '部门',
e.`name` AS '员工',
e.salary AS '工资'
FROM
employee e
WHERE
(
SELECT
count(em.salary)
FROM
employee em
WHERE
em.salary > e.salary
AND em.department = e.department
) < 3
ORDER BY
e.department,
e.salary DESC分组之后得到数组集合
JSON_ARRAYAGG函数
警告
JSON_ARRAYAGG() 这个函数可以将一组结果合成为一个JSON数组。 它是在 MySQL 5.7.22 及更高版本中引入的。
sql
SELECT department, JSON_ARRAYAGG(name) AS order_ids
FROM employee
GROUP BY department;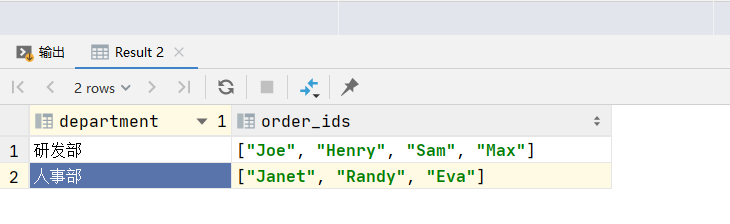
GROUP_CONCAT函数
警告
如果你使用的是MySQL的一个旧版本,不支持JSON_ARRAYAGG,你可以使用GROUP_CONCAT函数, 它可以将分组后的多个值连接为一个字符串,但输出格式为字符串,不是真正的数组。
sql
SELECT department, GROUP_CONCAT(name) AS order_ids
FROM employee
GROUP BY department;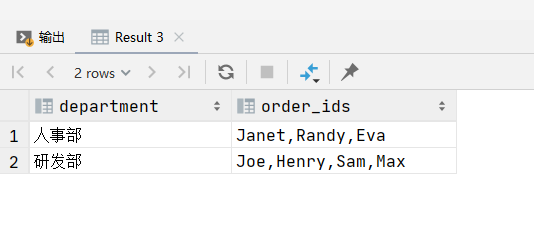
JSON_ARRAY创建JSON格式的数组
警告
这个函数用于创建一个JSON格式的数组。它是在 MySQL 5.7.8 版本首次引入的,与JSON相关的其他函数一起随着对JSON数据类型的支持一起推出
sql
SELECT JSON_ARRAY('apple', 'banana', 'cherry') AS fruitArray;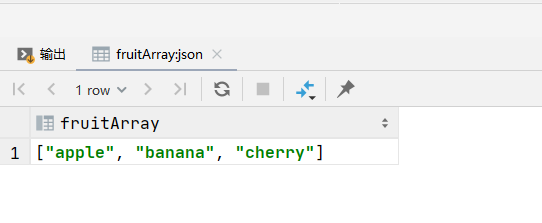
如何实现两个数组内容的合并?
高于5.7版本
MySQL提供了JSON_MERGE()(在MySQL 5.7.8-5.7.21版本中)或在MySQL 5.7.22及更新的版本中提供的JSON_MERGE_PRESERVE()和JSON_MERGE_PATCH()函数来实现JSON数组(或对象)的合并。
警告
JSON_MERGE_PRESERVE()函数将保留两个JSON数组中的所有元素。如果合并的JSON包含对象,JSON_MERGE_PRESERVE()在遇到同名的key时会将对应的value合并为一个新的数组。
sql
SET @json1 = JSON_ARRAY('apple', 'banana');
SET @json2 = JSON_ARRAY('cherry', 'date');
SELECT JSON_MERGE_PRESERVE(@json1, @json2) as merged_json;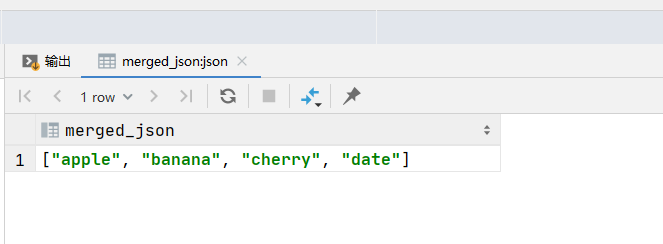
低于5.7版本
如果您的MySQL版本是5.7.22之前的,您可以使用JSON_MERGE()
sql
SET @json1 = JSON_ARRAY('apple', 'banana');
SET @json2 = JSON_ARRAY('cherry', 'date');
SELECT JSON_MERGE(@json1, @json2) as merged_json;行转列
sql
SELECT
o.orderId,
MAX(CASE WHEN l.status = 'status1' THEN l.createTime END) AS status1_time,
MAX(CASE WHEN l.status = 'status2' THEN l.createTime END) AS status2_time,
MAX(CASE WHEN l.status = 'status3' THEN l.createTime END) AS status3_time
FROM
OrderTable o
JOIN LogTable l ON o.orderId = l.orderId
GROUP BY
o.orderId;排列组合
sql
SELECT DISTINCT s1.color, s2.size
FROM sku s1, sku s2
WHERE s1.color IN ('红', '黄', '蓝') AND s2.size IN (10, 20);